
머신러닝 시스템의 종류
- 사람의 감독하에 훈련하는 것인지 그렇지 않은 것인지
- 지도 학습 (supervised learning)
- 비지도 학습 (unsupervised learning)
- 준지도 학습 (semisupervised learning)
- 강화 학습 (reinforcement learning)
- 실시간으로 점진적인 학습을 하는지 아닌지
- 온라인 학습
- 배치학습
- 훈련 데이터와 단순 비교인지, 패턴을 찾기 위해 예측 모델을 만드는지
- 사례 기반 학습
- 모델 기반 학습
- 위의 범주들은 배타적이지 않음 (e.g. 온라인 모델 기반 지도학습)
지도학습 (Supervised Learning)
- 머신러닝 용어
- 훈련 세트 (training set) : 머신러닝이 학습하는데 사용하는 샘플
- 훈련 사례 (trainig instance) : 각 훈련 데이터, 샘플 혹은 데이터 포인트
- 특성 (feature) : 데이터의 속성. 예측변수(predictor variable)라고도 함 / 특성(주행거리, 브랜드 등)을 통해 중고차 가격 예측
- 레이블 (label) : 지도학습에서 훈련 데이터에 포함되는 정답 / 중고차 가격이 레이블에 해당
- 지도학습은 명확한 정답 (Label, 결정값, 타깃)이 주어진 데이터를 학습
- 가장 널리 사용되는 지도 학습의 작업
- 분류(클래스 예측)
- 회귀(수치예측)
- 분류(Classification)
- 이진 분류 (binary classification) : 스팸 or 스팸 아님
- 다중 분류 (multiclass classification) : 개, 고양이, 새를 분류하는 문제
- 분류에서는 레이블의 범주(개, 고양이, 새)를 클래스(Class)라고 부름

- 회귀 (Regression)
- 연속된 숫자를 예측
- 교육수준, 나이, 주거지를 바탕으로 연간소득(타깃) 예측

- 대표적인 지도학습 알고리즘
- k-최근접 이웃 (k-Nearest Neighbors)
- 선형 회귀 (Linear Regression) --- 회귀 알고리즘
- 로지스틱 회귀 (Logistic Regression) --- 분류 알고리즘
- 서포트 벡터 머신 (Support Vector Machine, SVM)
- 결정 트리 (Decision Tree)와 랜덤 포레스트 (Random Forests)
- 신경망 (Neural Network)
비지도 학습 (Unsupervised Learning)
- 비지도 학습
- 훈련 데이터에 레이블(정답)이 없음
- 레이블이 없기 때문에 올바르게 학습되었는지 알고리즘을 평가하기 어려움
- 사진 애플리케이션에서 옆모습, 앞모습으로 군집되었다 해도 직접 눈으로 확인하기 전에는 결과를 평가하기가 어려움
- 비지도 학습은 데이터를 잘 이해하기 위해서(탐색적 분석) 사용되거나, 지도학습 알고리즘의 정확도 향상과 메모리/시간 절약을 위해 전처리 단계로 활용
- 대표적인 비지도 학습 알고리즘
: 군집 (Clustering)
- k-평균 (k-means)
- DBSCAN
- 계층 군집 (Hierarchical Clustering Analysis)
- 이상치 탐지 (Outlier Detection)
: 시각화, 차원 축소
- 주성분 분석 (Principal Component Analysis)
- t- SNE (t-distributed stochastic neighbor embedding)
: 연관 규칙 학습 (Association Rule Learning)
- 어프라이어리 (Apriori)
- 이클랫 (Eclat)
- 군집
- 블로그 방문자를 그룹으로 묶기(40%는 영화 애호가, 20%는 독서 애호가 등)
- 계층 군집(hierarchical clustering)을 알고리즘을 사용하면 각 그룹을 더 작은 그룹으로 세분화할 수 있음
- 고객, 마켓, 브랜드, 사회 경제 활동 세분화
- 시각화
- 레이블이 없는 대규모의 고차원 데이터를 2D, 3D로 변환하여 도식화 가능
- 가능한 한 구조를 그대로 유지하므로 데이터로부터 예상치 못한 패턴 발견
- 차원 축소
- 시각화와 비슷하게 너무 많은 데이터를 잃지 않으면서 데이터를 간소화
- 상관관계가 있는 여러 특성을 하나로 합침
- e.g) 특성1(차의 주행거리) + 특성2(연식) -> 특성3(차의 마모) : 특성 추출(feature extraction)이라고 함
- 차원 축소는 지도학습 같은 다른 알고리즘에 데이터를 주입하기 전에도 사용
- 이를 통해 실행속도와 디스크와 메모리 공간, 성능에 도움을 주기도 함
- 이상치 탐색 (anomaly detection)
- e.g) 부정 거래를 막기 위해 이상한 신용 거래 감지, 제조 결함 감지 등
- 학습 알고리즘에 주입하기 전에 데이터 셋에서 이상한 값을 자동으로 제거
- 시스템은 항상 샘플로 훈련되고, 새로운 샘플이 정상인지 이상치인지 판단
- 연관 규칙 학습 (association rule learning)
- 대량의 데이터에서 특성간의 흥미로운 관계를 찾음
- e.g) 슈퍼마켓 판매기록에서 "바베큐 소스와 감자를 구매한 사람이 스테이크도 구매
- 규칙 기반(ruled-based) 학습의 한 종류로 사이킷런에서 제공하지 않음
준지도학습 (Semi-supervised Learnig)
- 보통 레이블이 없는 데이터가 많고 레이블이 있는 데이터는 아주 조금임
- 군집을 통해 데이터를 분할하고 소수 레이블을 이용해 전체 그룹을 인식
- Google Photos, Facebook 사진 태그
- 이 서비스에 가족사진을 모두 올리면 사람 A는 사진 1, 5, 11에 있고, 사람 B는 사진 2, 5, 7에 있다고 자동으로 인식(군집)
- 사람마다 레이블이 하나씩만 주어지면 사진에 있는 모든 사람의 이름을 알 수 있고, 편리하게 사진을 찾을 수 있음
- 심층 신뢰 신경망(DBN)은 여러겹으로 쌓은 제한된 볼츠만 머신(RBM)이라 불리는 비지도 학습에 기초
- RBM이 비지도 학습으로 훈련된 뒤 전체 시스템이 지도학습으로 세밀하게 조정
강화학습 (Reinforcement Learning)
- 매우 다른 종류의 알고리즘(사이킷런에 없음)
- 주어진 환경(environment)에서 에이전트(agent)가 최대의 보상(reward)을 얻기 위해 최상의 정책(policy)을 학습
- 딥마인드의 알파고(Alpha Go)
배치학습과 온라인 학습 (batch learning & online learning)
- 배치 학습
- 가용한 데이터를 모두 사용하여 훈련시키는 오프라인 학습
- 이전 데이터와 새 데이터를 활용하여 새로운 버전의 모델을 학습
- 배치 학습도 훈련과 모델 런칭을 자동화할 수 있음
- 24시간, 혹인 1주일마다 학습
- 일반적으로 시간과 자원이 많이 소모
- 온라인 학습
- 샘플 한 개 또는 미니배치라 부르는 작은 묶음 단위로 훈련
- 학습 단계가 빠르고 비용이 적게 들어 데이터가 준비되는 대로 즉시 학습
- 연속적으로 데이터를 받고 빠른 변화에 적응해야 하는 시스템에 적합
- 컴퓨팅 자원이 제한된 경우에도 적합
- 사용한 샘플을 버릴지 보관할지 결정
온라인 학습 = 외부 메모리 학습
- 온라인 학습
- 컴퓨터 한대가 메인 메모리에 들어갈 수 없는 아주 큰 데이터 셋을 학습하는 시스템에도 온라인 학습 알고리즘 사용 가능
- 이를 외부 메모리(out-of-core) 학습이라고 함
- 알고리즘이 데이터 일부를 읽어 들이고 훈련 단계를 수행
- 전체 데이터가 모두 적용될 때까지 이 과정을 반복
- 점진적 학습(incremental learning) 이라고도 한다
사례 기반 학습
- 사례 기반(instance-based)학습
- 일반화 방법에 따라 사례 기반과 모델 기반 학습으로 나눔
- 시스템이 사례를 기억함으로써 학습
- 유사도 측정을 사용해 새로운 데이터에 일반화
- 예를 들어 스팸 메일과 공통으로 가지고 있는 단어가 많으면 스팸으로 분류
- k-최근접 이웃(k-Nearest Neighbors)

모델 기반 학습
- 모델 기반(model-based)학습
- 샘플로부터 일반화시키는 방법 : 모델을 만들어 예측에 사용(거의 대부분의 머신러닝 모델)

데이터 분석
- 데이터 분석 (1인당 GDP에 대한 삶의 만족도 조사)
- OECD 웹사이트에서 '더 나은 삶의 지표'와 IMF 웹사이트에서 '1인당 GDP' 데이터를 다운로드
- 시각화하여 데이터의 경향 파악(GDP가 올라갈수록 삶의 만족도가 선형적으로 올라감)


모델 선택
- 모델 선택
- 1인당 GDP의 선형 함수(linear function)로 삶의 만족도를 모델링(선형 회귀)
- 삶의 만족도 = θ 0 + θ 1 × 1 인당 GDP (θ 0 , θ 1 : 모델 파라미터)
- 아래 세 모델 중에 어떤 것이 최상의 성능을 낼 것인가?
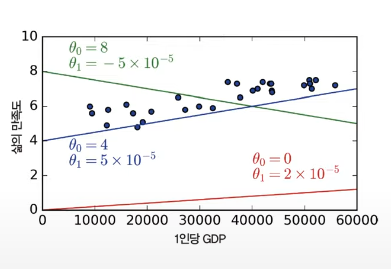
--> red, green 은 과소 적합, blue가 셋 중 최상의 성능을 낼 것으로 보인다.
비용 함수(Cost function)
- 좋은 모델을 고르기 위해서는?
- 측정 지표를 정해야 함
- 얼마나 좋은지를 측정하는 효용 함수로 정하거나 반대로 얼마나 나쁜지를 측정하는 비용 함수로 정할 수 있음
- 선형 회귀에서는 보통 예측과 타깃 사이의 거리를 재는 비용 함수를 사용
- 주어진 데이터에서 비용 함수의 값이 가장 작아지는 모델 파라미터(θ 0 , θ 1)를 찾는 과정을 훈련 또는 학습이라고 함
머신러닝 작업 요약
- 무언가 잘못되었다면
- 더 많은 특성(고용률, 건강, 대기오염 등)을 사용
- 좋은 훈련 데이터를 더 많이 확보
- 더 강력한 모델(다항 회귀 모델 등)을 선택
- 머신러닝 작업 요약
- 데이터를 분석
- 모델을 선택
- 훈련 데이터로 모델을 훈련(즉 비용 함수를 최소화하는 모델 파라미터를 찾기)
- 새로운 데이터에 대한 예측 만들기. 좋은 일반화를 기대
- 그리고 반복
머신러닝의 도전 과제
- 나쁜 데이터의 예
- 충분하지 않은 양의 훈련 데이터
- 대표성 없는 훈련 데이터
- 낮은 품질의 데이터
- 관련 없는 특성
- 나쁜 알고리즘의 예
- 훈련 데이터 과대 적합
- 훈련 데이터 과소 적합
- 머신러닝 모델 개선을 위해
- 데이터의 특성 파악
- 최적의 알고리즘과 파라미터를 구성하기 위한 끊임없는 노력
충분하지 않은 훈련 데이터
- 어린 아이는 '사과' 샘플 몇 개를 보고도 모든 종류의 사과를 구분
- 머신러닝은 아직 많은 데이터가 필요
- 정형화된 데이터 < 이미지 인식 < 음성 인식 (순서로 더 많은 데이터 필요)
- 믿을 수 없는 데이터의 효과
- 2001년 마이크로소프트 연구자들은 여러 종류의 모델에 충분한 데이터만 주어지면 '복잡한 자연어 중의성 해소'(문맥에 따라 two, to, too 중 어떤걸 써야 할지 아는 것) 문제를 잘 처리함을 증명
- 복잡한 문제에서는 알고리즘보다 데이터가 더 중요하다는 생각
- 그러나 여전히 중간 규모의 데이터셋이 많으므로 알고리즘을 무시하면 안됨
대표성 없는 훈련 데이터
- 일반화가 잘되려면 학습 데이터가 새로운 사례를 잘 대표하는 것이 중요
- 샘플이 작으면 우연에 의해 대표성 없는 데이터 생김(샘플링 잡음(noise))
- 큰 샘플도 표본 추출 방법이 잘못되면 대표성을 띄지 못함(샘플링 편향(bias))
- 유명한 샘플링 편향 사례
- 1936년 랜던과 루즈벨트의 대통령 선거에서 Literary Digest 사의 여론조사(랜던 57% 예측)
- 실제로는 루즈벨트가 60.8% 득표로 당선
- 여론 조사에 사용된 명부는 모두 공화당(랜던)을 투표할 가능성이 높은 부유한 계층에 편중
- 25%의 응답률로 정치에 관심 없는 사람들이 제외됨으로 표본이 편중되었음
낮은 품질의 데이터
- 학습 데이터가 에러, 이상치, 잡음으로 가득하다면 머신러닝 시스템이 내재되어 있는 패턴을 찾기 어려울 수 있음
- 전처리 작업이 필요
- 일부 샘플이 이상치일 경우 무시하거나 수동으로 고침
- 일부 샘플에서 특성이 몇 개 빠져있다면, 특성 전체를 무시할 지, 샘플을 무시할 지, 빠진 값을 채울지, 이 특성이 넣은 것과 뺀 것을 따로 훈련할지 정해야함
관련 없는 특성
- 성공적인 머신러닝 프로젝트의 핵심요소는 훈련(학습)에 사용할 좋은 특성들을 찾는 것 -> 특성 공학(feature engineering)
- 특성 선택(feature selection) : 가지고 있는 특성 중에서 가장 유용한 특성을 선택
- 특성 추출(feature extraction) : 특성을 결합하여 더 유용한 특성을 만듬
- 새로운 데이터로부터 새로운 특성을 만듬
과대 적합
- 과대 적합 (Overfitting)
- 해외 여행에서 택시 운전사에게 속았다면 그 나라의 모든 택시를 의심(일반화의 오류)
- 머신러닝에서도 과도하게 일반화를 하게 되면 과대적합 발생
- 이는 모델이 훈련 데이터에 너무 잘 맞지만 일반성이 떨어진다는 의미(실제로 이 모델의 예측을 믿기는 어려움)
- 훈련 세트에 잡음이 많거나 데이터셋이 너무 작으면 잡음이 섞인 패턴을 감지
- 과대적합을 피하기 위해
- 모델 파라미터 개수가 적은 모델을 선택(고차원 다항모델보다 선형모델)
- 훈련 데이터의 특성 수를 줄임
- 모델에 제약을 가하여 단순화 시킴(규제, regularization)
- 훈련 데이터를 더 많이 모으거나 잡음을 줄임(오류 데이터 수정, 이상치 제거 등)

- 규제가 모델의 기울기를 더 작게 만들어 훈련 데이터에는 덜 맞지만 새로운 샘플에는 더 일반화 되도록 함
- 규제의 양은 하이퍼 파리미터(hyperparameter)가 결정
<모델 파라미터 vs 하이퍼 파라미터 >
- 모델 파라미터
- 모델은 하나 이상의 파라미터(예를 들어 선형 모델의 기울기)를 사용해 새로운 샘플이 주어지면 무엇을 예측할지 결정
- 학습 알고리즘은 모델이 새로운 샘플에 잘 일반화 되도록 이런 파라미터들의 최적값을 찾음
- 하이퍼파라미터
- 하이퍼파라미터는 모델이 아니라 학습 알고리즘 자체의 파라미터(예를 들면 적용할 규제의 정도)
- 학습 알고리즘으로부터 영향을 받지 않으며 훈련 전에 미리 지정되고 훈련하는 동안 상수로 남아있음
과소 적합
- 과소 적합(Underfitting)
- 과대 적합의 반대
- 모델이 너무 단순해서 적절한 패턴을 학습하지 못함
- 예를 들어 삶의 만족도에 대한 선형 모델
- 해결 방법
- 모델 파라미터가 더 많은 강력한 모델을 선택
- 학습 알고리즘에 더 좋은 특성을 제공(특성 공학)
- 모델의 제약을 줄임(규제 하이퍼파라미터를 감소)
정리
- 머신러닝은 명시적인 규칙을 코딩하지 않고 데이터에서 학습
- 지도 학습 - 비지도 학습, 배치학습 - 온라인 학습, 사례 기반 학습 - 모델 기반 학습
- 학습 알고리즘은 주입된 데이터를 잘 표현하는 모델 파라미터를 도출
- 훈련 세트가 너무 작거나, 대표성이 없거나, 잡음이 많거나, 관련 없는 특성이 많다면 올바른 모델을 학습하지 못함
- 모델이 너무 복잡하거나(과대적합), 단순하지 않아야 함(과소적합)
테스트와 검증
- 훈련 세트와 테스트 세트
- 훈련 세트를 사용해 모델을 훈련
- 테스트 세트를 사용해 모델을 테스트
- 훈련 세트: 80%, 테스트 세트: 20%
- 테스트 세트에서 모델을 평가함으로써 새로운 샘플에 모델이 얼마나 잘 작동할지 예측할 수 있음
- 하이퍼 파라미터 최적화(ex. 규제적용)를 위해 테스트 세트를 사용하게 되면 새로운 데이터에서 잘 동작하지 않을 수 있음(과대적합)
- 즉 테스트 세트에서만 최적화된 모델이 만들어져 새로운 데이터에서 잘 동작하지 않을 수 있음
- 해결 방법
- 훈련 세트, 검증 세트, 테스트 세트로 나누고 검증 세트로 하이퍼파라미터를 조정
- 훈련 데이터에서 검증 세트로 너무 많은 양의 데이터를 뺏기지 않기 위해 교차 검증(cross-validation) 사용
- 훈련 세트와 검증 세트를 교번하여 여러번 검증 점수를 계산(교차 검증, cross-validation)
공짜 점심 없음 이론 (no free lunch)
- 1996년 데이비드 월퍼트가 어떤 가정도 없다면 특정 몯ㄹ이 뛰어나다고 판단한 근거가 없다는 이론
- 주어진 데이터 셋에 선형 모델이 잘 맞을지 신경망이 잘 맞을지 경험하기 전에 알 수 없음(결국 모든 모델을 평가해 봐야 한다)
- 하지만 보편적인 가이드는 정형화된 데이터에는 트리기반 앙상블과 지각에 관련된 데이터(이미지, 텍스트, 사운드)에는 신경망이 좋은 결과를 만든다
'Machine Learning' 카테고리의 다른 글
| 사이킷런 개요 (0) | 2022.09.01 |
|---|---|
| 파이썬 기반의 머신러닝 (0) | 2022.08.31 |
| 머신러닝 개요 (0) | 2022.08.31 |