
머신러닝의 예
- 우리 주변 머신러닝
- - 광학문자 판독기(OCR)
- - 스팸필터
- - 추천과 음성 검색으로 발전
- - 고객에 따른 타겟 광고
- - 선거 결과 예상, 도로 상태에 따른 신호 조절
- - 자연 재해의 경제적 측정 산출
- - 자동 운전 차량과 자동 항법 비행기 구현
- - 최근 많은 웹사이트와 기기가 머신러닝 알고리즘을 핵심 기술로 채택
- - 구글, 페이스북, 아마존, 넷플릭스
- 다양한 과학 분야
- - 별을 탐구하고 새로운 행성을 찾는 과제
- - 새로운 미립자를 발견하고 DNA 서열 분석
- - 맞춤형 암 치료법을 만드는 일 등
머신러닝이란
- "머신러닝" 은 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야다.(아서 사무엘, 1959)
- 어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때 경험 E로 인해 성능이 향상됐다면,
이 컴퓨터 프로그램은 작업 T와 성능 측정 P에 대해 경험 E로 학습한 것이다. (톰 미첼, 1997)
- 스팸 메일 구분하기 : 작업 T
- 훈련 데이터 : 경험 E
- 정확도 : 성능 측정 P
- 머신러닝은 데이터로부터 학습하도록 컴퓨터를 프로그래밍하는 과학(또는 예술)
왜 머신러닝인가
- 전통적인 프로그래밍 기법 : 규칙 기반 시스템 ( ruled based system )
- 스팸에 자주 나타나는 패턴 감지(메일 안의 단어 패턴 또는 보낸 이의 이름이나 메일 주소 등의 패턴..)
- 이 패턴을 발견했을 때 스팸으로 분류하는 알고리즘(규칙) 작성
- 프로그램을 테스트하고 위의 두 단계를 반복
- 단점: 규칙이 점점 복잡해지고 유지 보수가 힘들어짐

- 머신러닝 기법
- 스팸에 자주 나타나는 패턴을 감지
- 머신러닝 알고리즘이 스팸을 판단하는 기준을 스스로 학습
- 장점: 프로그램이 짧아지고, 유지보수가 쉬우며 정확도가 더 높음
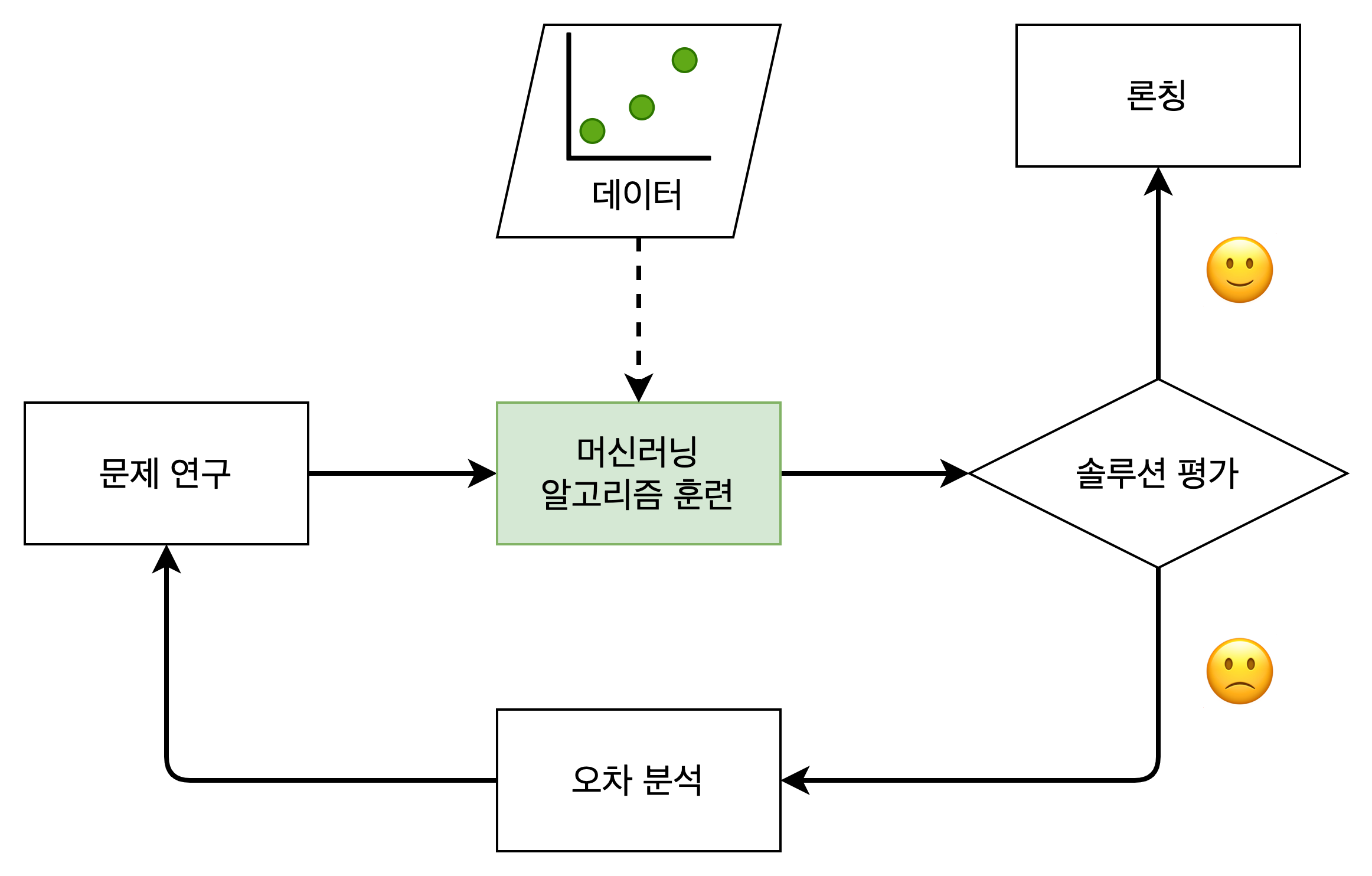
- 머신러닝이 유용한 분야
- 기존 솔루션으로는 많은 수동 조정과 규칙이 필요한 문제
- 전통적인 방법으로는 전혀 해결 방법이 없는 복잡한 문제 (음성인식, 얼굴인식)
- 변화하는 환경에 적응해야 하는 문제
- 복잡한 문제와 데량의 데이터에서 통찰 얻기 (데이터 마이닝)
데이터 마이닝이란
- 데이터 마이닝이란 무엇인가?
: 대량의 데이터로부터 그 안에 숨어있는 새롭고 가치있고, 의사결정에 유용한 정보를 찾는 작업
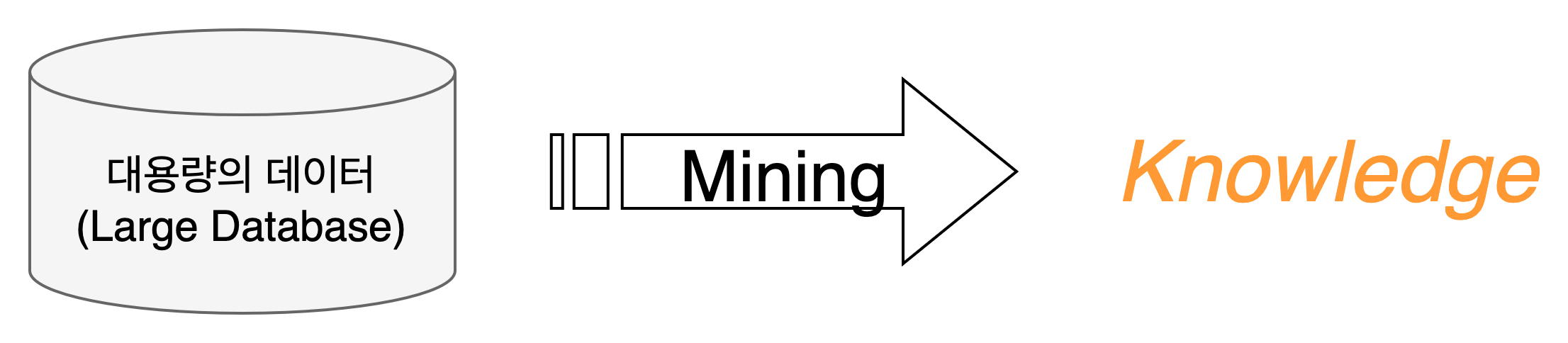
머신러닝 vs 데이터 마이닝
- 데이터 마이닝은 데이터 안에 알려지지 않은 속성을 찾는 것이 주 목적
- 머신 러닝은 데이터의 알려진 속성들을 학습하여 예측 모델을 만드는것이 목적
- 데이터 마이닝 뿐만 아니라 컴퓨터 과학(Computer Science)이나 통계학(Statistics)에서도 비슷한 개념을 다룸
- 따라서 머신 러닝은 이 세가지 학문 분야에 모두 걸쳐있음
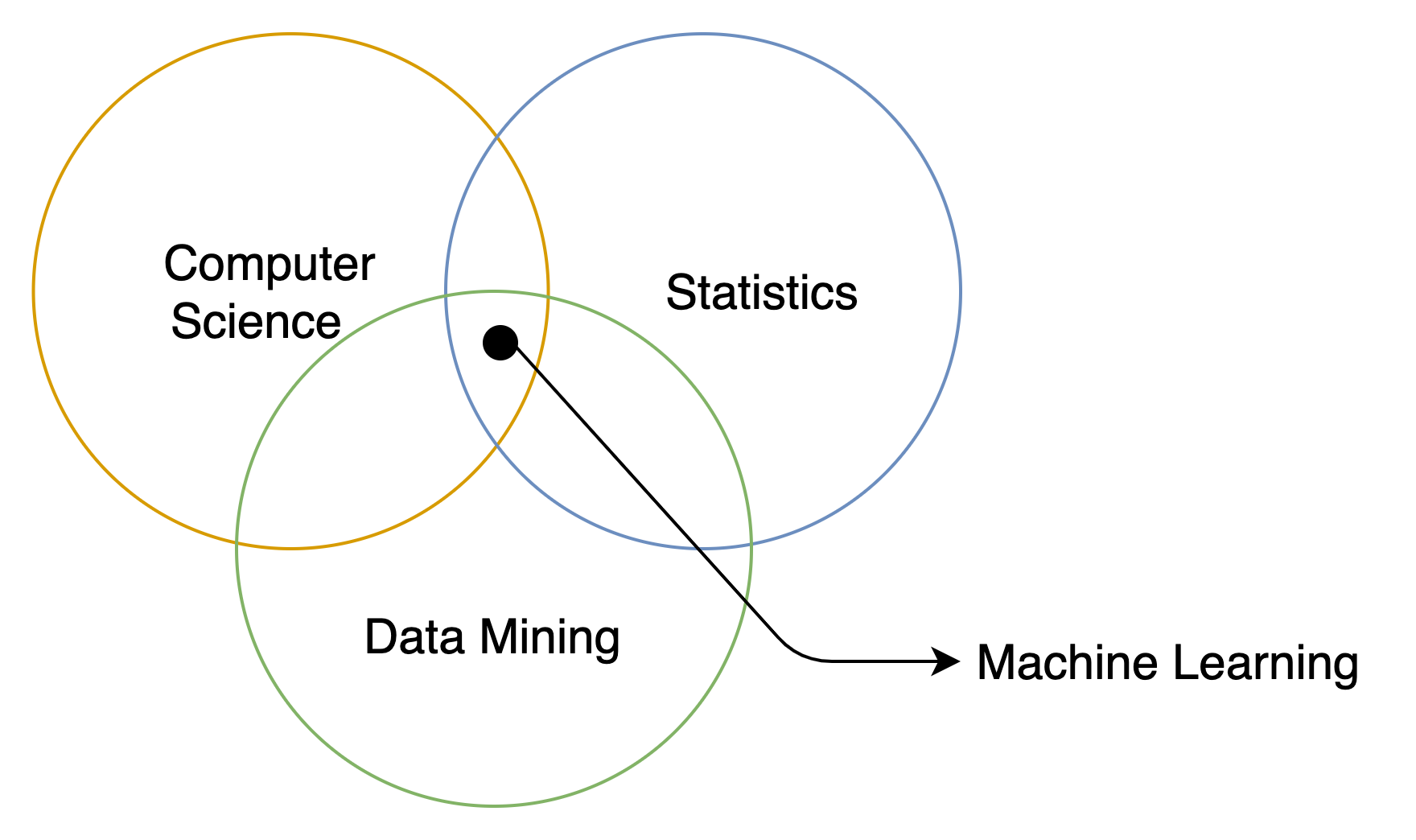
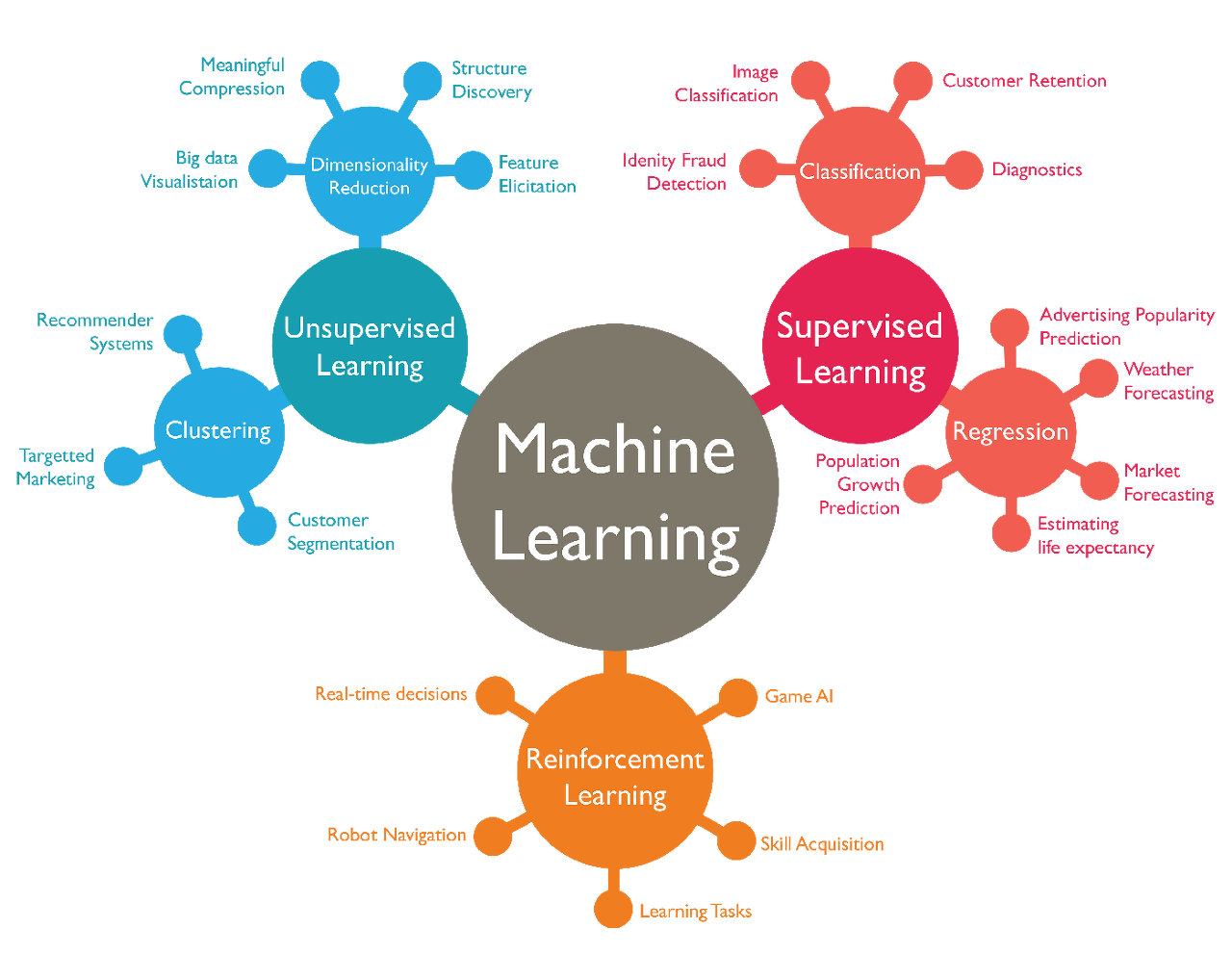
머신러닝 기반의 예측 분석
'Machine Learning' 카테고리의 다른 글
| 사이킷런 개요 (0) | 2022.09.01 |
|---|---|
| 머신러닝 알고리즘의 개요 (1) | 2022.08.31 |
| 파이썬 기반의 머신러닝 (0) | 2022.08.31 |